《In Search of an Understandable Consensus Algorithm》译文
- Replicated state machines
- What’s wrong with Paxos?
- Designing for understandability
- The Raft consensus algorithm
- Cluster membership changes
- Clients and log compaction
- Implementation and evalution
目录
- Abstract
- 1 Introduction
- 2 Replicated state machines
- 3 What’s wrong with Paxos?
- 4 Designing for understandability
- 5 The Raft consensus algorithm
- 6 Cluster membership changes
- 7 Clients and log compaction
- 8 Implementation and evalution
Abstract
Raft是一种用于管理复制日志(replicated log)的共识算法。它能产生和(multi-)Paxos相同的结果,且和Paxos一样有效。但是,它的结构却不同于Paxos;这让Raft比Paxos更易于理解,也为构建实际系统提供了更好的基础。为了增强可理解性,Raft将例如领导者选举, 日志复制与安全性等关键共识元素进行了分离,并且提供了更强的一致性,目的是减少必须考虑的状态。用户调查的结果显示,Raft比Paxos更易于学生学习。Raft包含了一种改变集群成员的新机制,通过大量重叠(overlapping majority)来保证安全性。
1 Introduction
共识算法允许一组机器像一致的的整体一样工作,即使其中一员发生故障也不会出现问题。因此,它在构建可靠的大规模软件系统的过程中起着关键的作用。Paxos一直主导着过去十年间对共识算法的讨论:大多数共识的实现都基于Paxos或者受其影响。Paxos已经成为了用来教授共识算法给学生的主要工具。
不幸的是,尽管已经做了大量努力去化简Paxos,但它还是太难以理解了。另外,它的结构需要做复杂的改变来支持实际的系统。因此,系统架构师和学生都对Paxos感到困扰。
在切身的被Paxos困扰之后,我们决定实现一种新的共识算法,使之可以为系统的构建和教学提供更好的基础。我们的主要目标是让它更易于理解,所以我们的方法有些不同寻常:我们是否能以一种比Paxos更易于理解的方式为实际的系统定义一个共识算法?此外,我们想要该算法能更好的被直观理解,而这对系统构建者很重要。算法生效很重要,但是,能清楚地显示它为什么生效也同样重要。
这项工作的结果就是一个名为Raft的共识算法。在设计Raft的时候,我们使用了一些额外的技术用于提供可理解性,包括分解(Raft分离了领导者选举, 日志复制与安全性)以及状态空间的缩减(相较于Paxos,Raft降低了不确定性以及sever间达到一致的方法)。一个由来自两个大学的43位学生参与的用户调查显示Raft要比Paxos易于理解的多;在同时学习了两种方法之后,他们中的33名学生回答Raft的问题要好于Paxos。
Raft在很多方面和现存的共识算法类似(最值得注意的是Oki和Liskov的Viewstamped Replication [27, 20]),但是它有以下这些独特的特性:
- Strong leader:Raft比其他共识算法使用了更强形式的leadership。比如,日志记录(log entry)只能从leader传给其他server。这简化了对于replicated log的管理并且使Raft更加易于理解。
- Leader election:Raft使用随机的时钟来选举leader。这只是在原来所有共识算法都需要的heartbeats基础上增加了一小部分机制,但是却简单快速地解决了冲突。
- Membership changes:Raft通过一种新的joint consensus的方法来实现server集合的改变,其中两个不同配置下的majority在过度阶段会发生重合。这能让集群在配置改变时也能继续正常运行。
不论对于教学还是作为实现系统的基础,我们相信Raft都要优于Paxos和其他的共识算法。它比其他算法更简答也更加易于理解;它能完全满足实际系统的需求;它有很多开源的实现并且已经被很多公司使用;它的安全性已经被充分证实了;并且它和其他算法一样地有效。
论文的剩余部分介绍了replicated state machine问题(Section 2)、讨论了Paxos的优缺点(Section 3)、描述了可理解性的一般方法(Section 4)、描述了Raft 共识算法(Section 5-7)、评估Raft(Section 8)、最后论述有关工作(Section 9)。受限于篇幅,Raft中的一些元素在这里省略了,但是它们可以在一份扩展的技术报告[29]中找到。其余内容描述了client如何和系统进行交互以及如何回收Raft log空间。
2 Replicated state machines
共识算法通常出现在replicated state machiness[33]的上下文中。在这种方法中,一组server上的状态机(state machine)对同一个状态的拷贝进行计算,即使其中一些server宕机了也能正常运行。Replicated state machine通常用于解决分布式系统中的容错问题。例如,拥有单一集群 leader的大规模系统,例如GFS[7]、HDFS[34]和RAMCloud[30]通常会用一个单独的replicated state machine来管理leader选举以及存储用于挽救leader崩溃的配置信息。Replicated state machine典型的例子包括Chubby[2]和ZooKeeper[9]。
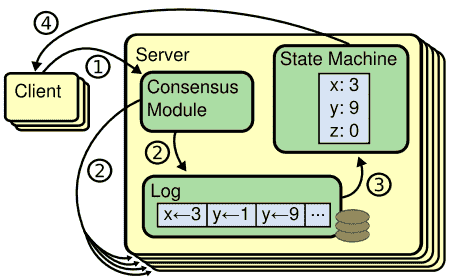
Replicated state machine通常用replicated log来实现,如Figure 1所示。每一个server存储了一个包含一系列命令的log,而它的状态机按顺序执行这些命令。每个日志以同样的顺序包含了同样的指令,所以每一个状态机都会处理相同的命令。由于每一个状态机都是确定的,因此计算将得到同样的状态和输出结果。
共识算法的作用是保证replicated log的一致性。server中的共识模块用于从client处接收命令并且将它们加入log。它会和其他server的共识模块进行通信,从而确保每一个log都以同样的顺序包含同样的请求,每一个server的状态机都按顺序处理它们的log,并且将输出返回给client。最终,这些server呈现出的是一个单一的,高度可靠的状态机。
用于实际系统的共识算法通常具有以下特性:
- 在所有的非拜占庭(non-Byzantine)条件下要确保正确性(从不返回一个错误的结果),包括网络延迟或分区,以及网络包的丢失、重复和乱序。
- 只要大多数server是可操作的、能相互通信的、并且可以和client进行通信的,那么系统必须是可用的。因此,一个由五台server组成的集群必须能忍受两台server的故障。一个server发生故障时,可能是暂停了;它可能稍后会恢复到存储在stable storage中的状态并且重新加入集群。
- 它们不依赖于时间来确保log的一致性:最差的情况下,fault clocks和extreme message delays会导致系统的不可用问题。
- 通常情况下,当集群中的大多数server已经对单一的RPC做出相应时,可以认为一个命令完成了。少数反应慢的server不应该影响整个系统的性能。
3 What’s wrong with Paxos?
在过去的十年中,Leslie Lamport的Paxos协议[13]几乎成为了共识的代名词:它是在课堂上最常被教授的协议,并且很多共识的实现都以它作为起点。Paxos首先定义了在单一decision上能够达到一致的协议,例如一个单一的replicated log entry。我们将这样的一个子集称之为single-decree Paxos。接下来,Paxos可以将该协议的多个实例组合在一起去形成一系列的decision作为log(multi-Paxos)。Paxos保证了safety和liveness,并且支持cluster membership的改变。它的正确已经经过证明,并且在一般的情况下也是高效的。
不幸的是,Paxos有两个严重的缺陷。第一个缺陷是Paxos太难以理解了。它的完整描述[13]是有名的难懂;很少有人能完全理解它,即使可以也需要巨大的努力。因此,已经做了很多尝试,尝试以更简单的版本[14,18,19]去解释Paxos。虽然这些尝试都着力于single-decree版本,但是仍面临着挑战。在一项针对NSDI 2012与会者的调查中,我们发现很少有人对Paxos感到舒服,即便是那些经验丰富的研究人员。我们自身也对Paxos感到非常痛苦,我们在不能理解完整的协议,直到我们阅读了几个简化版的描述并设计了我们的替代协议,整个过程持续了近一年。
我们认为Paxos的晦涩来源于它将single-decree subset作为自己的基础。Single-decree Paxos很难懂,也很隐晦:它被划分为两个不能用直觉来解释的阶段并且不能单独理解。因此,这就导致了很难对single-decree protocol是如何工作的建立起直觉。而multi-Paxos的composition rule则更加添加了复杂性。我们坚信对于在multiple decision的情况下到达consensus这个问题肯定能以其他更直接,更明显的方式被分解。
Paxos的第二个问题是它没有为具体实现提供一个很好的基础。一个原因是对于multi-Paxos没有一个广受认可的算法。Lamport的描述主要针对的是single-decree Paxos;他概述了实现multi-Paxos的可能途径,如[24],[35]和[11],但是缺少很多细节。对于充实以及优化Paxos已经做过很多努力,但是它们之间,以及和Lamport的概述都不相同。像Chubby[4]这样的系统已经实现了类Paxos算法,但是它的很多细节并没有公开。
另外,Paxos的架构也不适合构建实际系统;这是它按single-decree分解的另一个后果。例如,独立地选取一组log entry并且将它们融合成一个顺序的log并没有什么好处,仅仅只是增加了复杂度。相反,围绕按顺序扩展的log来设计一个系统是更简单和高效的。Paxos的另一个问题是它将对称的peer-to-peer作为核心(虽然在最后为了优化性能提出了一种弱形式的leadership)。这在只需要做一个decision的简单场景中是可行的,但是很少有实际的系统会使用这种方法。如果要有一系列的decision要决定,那么简单且快速的做法是先选出一个leader,然后再让leader去协调decision。
因此,实际系统和Paxos都没什么相同之处。各种实现都以Paxos开始,然后发现实现起来很困难,最后只能开发出了一个完全不同的架构。这是极其费时且易出错的,而Paxos的难以理解则更加加剧了这个问题。Paxos的正确性理论很好证明,但是具体实现和Paxos太过不同,因此这些证明就没什么价值了。接下来这段来自Chubby的评论是非常典型的:
“Paxos算法的描述和现实世界的系统的需求之间有巨大的矛盾….而最终的系统都将建立在一个未经证明的协议之上”
因为这些问题的存在,我们得出这样的结论,Paxos并没有为实际系统的构建和教学提供一个很好的基础。基于在大规模软件系统中consensus的重要性,我们决定尝试能否设计出另外一种比Paxos有着更好性质的共识算法。而Raft就是我们实践的结果。
4 Designing for understandability
我们在设计Raft的时候有以下几个目标:它必须为系统的构建提供完整并且实际有效的基础,而这能极大地减少开发者的设计工作;它必须在所有条件下都是安全的,在典型的操作条件下是可用的;它在通常的操作中也必须是高效的。但我们最重要的目标,也是最大的挑战,就是可理解性。我们必须让广大的读者能相对轻松地理解这个算法。并且要能够构建对这个算法的感觉,从而让系统构建者能做一些实际实现中必要的扩展。
在设计Raft的很多点上,我们要在很多可选方法之间做出选择。在这些情况下,我们基于可理解性对这些方法进行评估:对于每一个可选方案的描述是否困难(比如,它的状态空间的复杂度是多少,以及它是否有subtle implication?)以及读者是否能轻松地完全理解这种方法和它的含义。
后来我们意识到这种分析方法具有很强的主观性;于是我们使用了两种方法让分析变得更具通用性。第一种是广为人知的问题分解方法:我们能否将问题分解为可以被相对独立地解释,理解并且被解决的几部分。例如,在Raft中,我们分解了leader election, log replication, safety和membership changes这几部分。
我们的第二种方法是通过减少需要考虑的状态数,尽量让系统更一致以及尽可能地减少非确定性,以此简化状态空间。具体来说,log不允许存在漏洞(hole),Raft限制了log之间产生不一致的途径。虽然在大多数情况下,我们都要减少不确定性,但是在某些情况下,不确定性确实提高了可理解性。特别地,随机化的方法会引入不确定性,但是通过以相同的方式处理所有可能的选择(choose any; it doesn’t matter),确实减少了状态空间。我们就使用了随机化来化简Raft的leader election算法。
5 The Raft consensus algorithm
Raft是一种用于管理Section 2中所描述的形式的replicated log的算法。Figure 2以精简的形式总结了这一算法,而Figure 3列出了该算法的关键特性,而这些特性将在本节的剩余部分分别进行讨论。
Raft首先通过选举一个顶层的leader来实现共识,然后把管理replicated log的责任全部给予这个leader。leader从client处接收log entry,再将它备份到其他server中,接着告诉server什么时候能安全地将log entry加入state machine中。leader的存在简化了replicated log的管理。比如,leader可以在不询问其他server的情况下决定将新的entry存放在log的什么位置并且数据简单地从leader传给其他server。leader可能会发生故障或者和其他server断开,在这种情况下会有新的leader被选举出来。
通过选举leader,Raft将共识问题分解成三个相对独立的子问题,它们会在接下来的子章节中讨论:
- Leader election:如果现存的leader发生故障,必须选举出一个新的leader(Section 5.2)
- Log replication:leader必须从client处接收log entry并且将它们在集群中进行备份,强制使其他log与它自己一致(Section 5.3)
- Safety:Raft中最关键的safety property就是Figure 3所示的State Machine Safety Property:如果有任何的server已经将一个特定的log entry加入它的state machine中,那么其他的server对于同一个log index的log entry必须相同。Section 5.4 描述了Raft如何确保这个性质; 该解决方案涉及对Section 5.2中描述的选举机制的额外限制。
![Figure 2: Raft共识算法的浓缩总结(不包括成员变更和日志压缩)。左上角框中的服务器行为被描述为一组独立且重复触发的规则。如 Section 5.2 指出在哪里讨论了特定的特性。一份正式规范[28]更精确地描述了算法。](/2022/01/21/%E3%80%8AIn-Search-of-an-Understandable-Consensus-Algorithm%E3%80%8B%E7%BF%BB%E8%AF%91/Figure2.png)
在展示了共识算法之后,本节将讨论可用性以及时间在系统中扮演的角色。

5.1 Raft basics
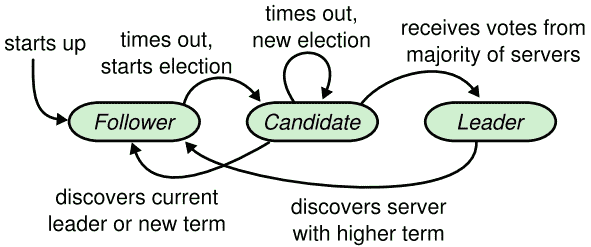
一个Raft集群包含多个server;一般是五个,因此系统能忍受两台机器的故障。在任意给定时刻,每个server都处于以下三个状态中的一个:leader、follower或者candidate。在正常情况下,只有一个leader,其他都是follower。follower是被动,它们不会自己发送请求,只是简单地对来自leader和candidate的请求进行回复。leader会对所有来自client的请求进行处理(如果一个client和follower进行交互,follower会将它重定向给leader),第三种状态candidate,是用来选举Section 5.2中描述的新的leader。Figure 4显示了各种server状态以及它们之间的转换;关于转换将在下文进行讨论。
Raft将时间划分成任意长度的term,如Figure 5所示。Term以连续的整数进行编号。每个term以一次election开始,这个阶段会有一个或多个candidate竞选leader,如Section 5.2所示。如果一个candidate竞选成功,那么它将在term剩下的时间里作为leader。在有些情况下,一个election可能导致一次分裂投票(split vote)。在这种情况下,term将以一种没有leader的状态结束;而一个新的term(伴随新的选举)将立即开始。Raft将保证在一个term中,最多只有一个leader产生。
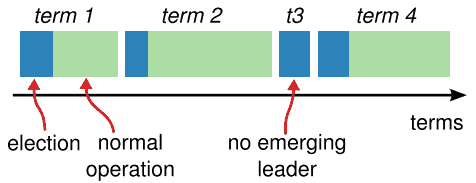
不同的server可能在不同的时间观察到term的转换,而在有些情况下,一个server可能会观察不到选举甚至是一个完整的term。term在Raft中起到的是逻辑时钟的作用,它能够让server去检测那些需要淘汰的信息,如过时的leader。每个server都存储了一个当前任期数(current term number),它会随时间单调递增。当前任期数会随着server之间的通信而改变;如果一个server的当前任期数比其他的小,那么它就会将自己的当前任期数更新到更大的值。如果一个candidate或者leader发现它的term已经过时了,那么它就会自觉恢复到follower状态。如果一个server收到另一个过时任期的server请求,那么会拒绝它。
Raft servers之间通过RPC进行通信,而共识算法需要两种类型的RPC。RequestVote RPC由candidate在election期间发起(Section 5.2),AppendEntries RPC由leader发起,用于备份log entry和提供heartbeat(Section 5.3)。如果一个server没有收到回复,那么它会及时重发RPC,并以并行方式发送RPC来提高性能。
5.2 Leader election
Raft使用一种heartbeat机制来触发leader选举。当server启动的时候,默认作为follower。server如果能持续地从leader或者candidate处获取有效的RPC,那么它将始终保持follower状态。为了保持自己的权威性,leader会阶段性地发送heartbeats(不带有log entry的AppendEntry RPC)给所有的follower。如果一个server在名为election timeout的时间段中没有收到交互信息,那么它就会认为不存在一个 有效的leader,并且发起新的一轮选举来选出一个新的leader。
为了开始一轮选举,follower会增加它的当前任期数并且转换为candidate状态,接着投票给自己,然后并行地给集群中的其他server发送RequestVote RPC。candidate将持续保持这种状态,直到以下三个条件中的一个被触发:(a)它赢得了选举,(b)另一个server宣布它自己是leader,(c)过了一段时间之后也没有赢得选举的server。这些情况将在接下来分别进行讨论。
如果一个candidate在一个term内收到了来自集群中的大多数server的投票,那么它将赢得选举。每一个server在每个term中都最多会给一个candidate投票,并且基于first-come-first-serverd原则(Section 5.4中将对于投票添加一个额外的约束)。大多数原则确保了在一个给定的term中最多只有一个candidate可以赢得选举(Figure 3中的Election Safety Property)。一旦一个candidate赢得了选举,它将成为leader。之后它将向所有其他的server发送hearbeat用以明确自己的权威并且阻止新一轮的选举。
当在等待投票时,一个candidate可能会收到来自另一个server的AppendEntry RPC声称自己是leader。如果该leader的term(包含在该RPC中)大于等于candidate的当前任期数,那么candiate认为该leader是有效的并且返回到follower的状态。如果RPC中的term小于candidate的当前任期数,那么candidate会拒绝该RPC并且保持candidate状态。
第三种可能的情况是一个candidate在选举中既没有赢也没有输:如果在同一时刻有很多follower成为了candidate,选票将会因为分裂而没有candidate会获得大多数选票。当这种情况发生时,每个candidate都会发生timeout并且通过增加term和发送新一轮的RequestVote RPC来开始新的选举。然而如果没有额外的措施,分裂投票(splite vote)可能会一直重复下去。
Raft使用随机的election timeout来确保split vote很少发生并且保证即使发生了也很快会被解决。为了在一开始就避免split ovte,election timeout会在一个固定区间内随机选择(如 150-300ms)。这就将server错开从而保证在大多数情况下只有一个server会timeout;它将赢得选举并且在其他的server超时之前发送heartbeat。同样的机制也被用在处理split vote上。每个candidate在选举开始的时候重新随机确定一个election timeout并在下一次election开始前静止等待timeout的到来;这就减少了在下一轮选举时发生split vote的可能。Section 8.3展示了使用这种方法快速选择一个leader的过程。
选举过程是一个能很好显示易理解性指导我们做出设计选择的例子。一开始我们计划使用一个rank system:每个candidate都会赋予一个唯一的rank,它会被用来在相互竞争的candidate之中做出选择。当一个candidate发现另一个candidate有更高的rank,那么它就会退回到follower的状态,从而让有更高rank的candidate能更容易赢得下一轮election。但我们发现这种方法会在可用性方面产生一些不易察觉的问题(如果有着更高rank的server发生了故障,一个低rank的server可能需要timeout并且重新成为candidate,但是这个过程发生地太快,则会引发新的leader选择过程)。我们对这一算法做了多次调整,但是每次调整之后都有新的极端情况(corner cases)产生。最后我们得出结论:随机重试的方法是更明显和更易于理解的方法。
5.3 Log replication
一旦一个leader被选择出来以后,它开始处理client的请求。每个client请求都包含了需要由replicated state machine执行的命令。leader用命令扩展log,作为新的entry,然后并行地给其他server发生AppendEntry RPC来备份entry。当该entry被安全地备份之后(如下所述),leader会让它的state machine执行该entry,并且将执行结果返回给client。如果follower崩溃了或者运行很慢,亦或是丢包的话,leader会不停地重发AppendEntry RPC直到所有的follower最终都保存了所有的log entry。
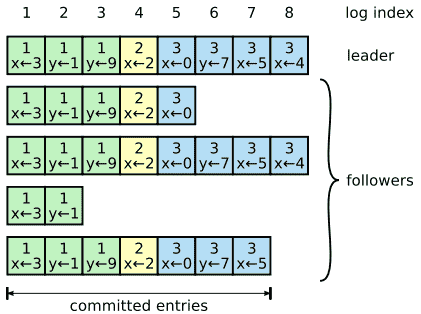
Log以Figure 6中的形式被组织。当一个entry被leader接收的时候,每个log entry都会包含一个state machine命令和term number。log entry中的term number是用来检测log之间是否一致并且确保Figure 3中的一些特性的。同时,每个log entry都有一个整数型的index用于标示它在log中的位置。
leader决定何时让state machine执行log entry是安全的,而这样的entry被称为committed。Raft保证所有committed entry都是持久的(durable)并最终会被所有可用的state machine执行。一旦创建它的leader已经将它备份到大多数server中,log entry就会被committed(例如Figure 6中的entry 7)。同时它也会commit leader的log中所有前面的entry,包括那些由之前leader创建的entry。Section 5.4中会讨论在leader改变之后应用这条规则会产生的一些微妙的问题,同时它也会说明这样关于commitment的定义是安全的。leader会追踪它已知被committed最高的index,并且会在之后的AppendEntry RPC(包括heartbeat)包含此index,从而让其他server能读取它。一旦follower知道了一个log entry被committed,它会将这个entry应用于本地的state machine(以log的顺序)。
我们设计了Raft log mechanism来保持不同server的log间的高度一致性。这不仅简化了系统行为而让它们可预测,并且这也是确保安全性的重要组件。Raft维护了以下特性,它们合起来构成了Figure 3所示的日志匹配性(Log Matching Property):
- 如果不同的log中的两个entry有着相同的index和term,那么它们存储相同的command。
- 如果不同的log中的两个entry有着相同的index和term,那么它们前面的entry都是相同的。
第一个性质保证了leader对于给定log的index和term,它最多产生一个entry,并且log entry永远不会改变它在log中的位置。第二个特性则由AppendEntry一个简单的一致性检查来保证。在发送一个AppendEntry RPC的时候,leader会在其中包含新entry前面entry的index和term。如果follower没有在log中有同样index和term的entry,那么它就会拒绝这个新entry。一致性检查起到了归纳步骤(induction step)的作用:log的initial empty state是满足Log Matching Property的,而一致性检查则在log扩展的时候保证了Log Matching Property。因此,当AppendEntry成功返回的时候,leader就知道该follower的log和自己是否一致。
在进行正常操作的时候,leader和follower的操作始终是一致的,因此AppendEntry的一致性检查永远不会失败。但是,leader的崩溃会导致log处于不一致的状态(老的leader可能还没有将它log中的所有entry完全备份)。而这些不一致性可能随着一系列的leader与follower的崩溃而叠加。Figure 7说明了follower的log可能和新的leader不一致的情况。follower中可能会遗漏一些leader中的entry,同时它里面也可能有一些leader中没有的额外的entry,或者两者都有。log中遗失的或者额外的entry中可能跨越多个任期。
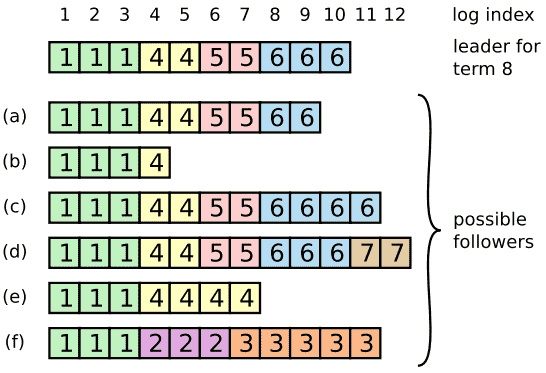
为了让follower的log和自己保持一致,leader必须找到最后使二者log一致的entry,并且删除follower中该entry之后所有的entry。所有这些操作都用于回应AppendEntry RPC的一致性检查。leader为每一个follower都维护一个nextIndex,它代表了leader将会发送给follower的下一个log entry的编号。当一个leader刚刚开始运行的时候,它会将所有的nextIndex都初始化为它自己log的最后一个entry的index + 1(Figure 7中的11)。如果follower和leader的log不一致,AppendEntry RPC的一致性检查会在下一个AppendEntry RPC的时候失败。在收到一个rejection之后,leader会减小它的nextIndex并且重发AppendEntry RPC。最终nextIndex会达到leader和follower的log匹配的状态。此时,AppendEntry会成功返回,删除follower的log中不一致的entry并且会根据leader的log进行扩展(如果有的话)。一旦AppendEntry成功,follower已经和leader的log一致了,而且将在term的接下来部分保持。该协议可以通过减少rejected AppendEntry RPC的数目来优化。
在这种机制下,leader不用在它刚刚成为leader的时候执行任何额外的操作用于恢复log的一致性。它只用正常地开始运行,并且log会随着AppendEntry一致性检查的失败而不断收敛。leader从来不会重写或者删除它自己log的entry(Figure 3中的Leader Append-Only Property)。
该log replication mechanism展示了Section 2中想要达到的一致性(consensus property):Raft可以接收、备份并执行新的log entry,只要有大多数server正常运行;在正常情况下,一个新entry会在仅一轮RPC中被备份到集群的大多数server中;因此一个运行较慢的follower并不会影响性能。
5.4 Safety
在前面的章节中描述了Raft如何选举leader以及备份log entry。但是之前描述的机制并不足以保证每个state machine以同样的顺序执行同样的command。例如,follower可能在leader commit多个log entry的时候一直处于不可用的状态,而之后它可能被选作leader并且用新的entry覆写这些entry;因此,不同的state machine可能会执行不同的command序列。
本节中,我们通过给哪些server能被选举为leader增加约束来完善Raft算法。该约束确保任何term的leader会包含之前term所有commit的entry(Figure 3中的Leader Completeness Property)。通过增加election restriction,我们更加细化了commitment的规则。最后,我们给出了Leader Completeness Property的证明概述并展示了它如何规范了replicated state machine的操作。
5.4.1 Election restriction
任何基于leader的共识算法,leader最终都必须存储所有的已提交entry。在一些共识算法中,例如Viewstamped Replication[20],即使一开始没有包含全部的已提交entry也能被选为leader。这些算法都会包含额外的机制用于识别遗失的entry并且将它们传给新的leader,要么在election期间,要么在不久之后。不幸的是,这需要额外的机制和更高的复杂度。Raft使用了一种更简单的方法,它保证在选举期间每个新的leader都包含了前面term包含的所有entry,从而不需要将这些entry传给leader。这意味着log entry的流动是单方向的,只从leader流向follower,而leader从不会重写log中已有的entry。
Raft用投票程序(voting process)来防止那些log中不含全部committed entry的candidate成为leader。candidate为了赢得选举必须和集群的大多数server进行交互,这意味着每个committed entry必须在大多数server中存在。如果一个candidate的log至少和一个大多数server子集群的log保持up-to-date(”up-to-date”将在下文精确定义),那么它就包含了所有committed entry。RequestVote RPC实现了这一约束:RPC中包含了candidate的log信息,如果voter自身的log比该candidate的log更up-to-date,那么它会拒绝投票。
Raft通过比较log中最近一个entry的index和term来确定两个log哪个更up-to-date。如果两个log的last entry有不同的term,那么拥有较大term的那个log更up-to-date。如果两个log以相同的term结束,那么log更长的那个就更up-to-date。
5.4.2 Committing entries from previous terms
如Section 5.3中所述,一旦该entry已经被大多数个server存储了,leader就知道current term中的entry已经被提交了。如果一个leader在committing an entry之前就崩溃了,那么新leader就会尝试完成该entry的备份。可是一旦前面term的entry被存储于大多数个server中,leader就很难立刻确定它是否已经committed。Figure 8展示了这样一种情况,一个旧log entry已经被存储在大多数个server中,但是它仍然可以被新leader重写。
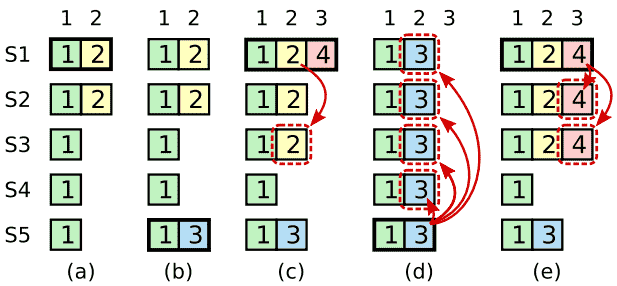
为了防止Figure 8中这样问题的发生,Raft不会通过计算备份的数目来提交之前term的log entry。只有leader当前term的log entry才通过计算备份数committed;一旦当前term的entry以这种方式被committed了,那么之前的所有entry都将因为Log Matching Property而被间接committed。其实在很多情况下,leader可以非常安全地确定一个旧entry已经被committed了(比如,如果该entry已经被存储在所有server中了),但是Raft为了简单起见使用了一种更保守的方法。
因为leader从之前的term备份entry时,log要保留之前的term number,这会让Raft在提交规则中引入额外的复杂度。在其他共识算法中,如果一个新的leader从之前的term备份entry时,它必须使用它自己的新的term number。因为log entry的term number不随时间和log的不同而改变,这就能让Raft更加容易地进行推导。另外,Raft中的新的leader与其他算法相比只需要从之前的term传输更少的log entry(其他的算法必须在传输备份的log entry被committed之前进行重新编号)。
5.4.3 Safety argument
给出了完整的Raft算法之后,我们可以进一步论证leader完整性(Leader Completeness Property)成立(该论据基于safety proof;参见Section 8.2)。我们假设leader完整性是不成立的,并推出矛盾。假设term T的leader(leaderT) commit了一个该term的log entry,但是该log entry并没有被新term的leader存储。考虑满足大于T的最小的term U,它的leader(leaderU)没有存储该entry。
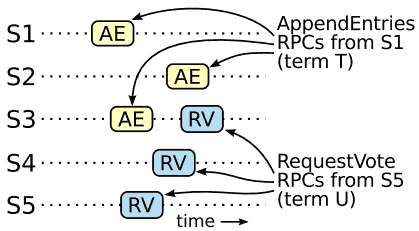
- 在leaderU选举期间,该committed entry一定不存在于它的log中(leader从不删除或者重写entry)。
- leaderT将entry备份到了集群的大多数server中,并且leaderU获取了来自集群的大多数的投票,如Figure 9所示。而voter是产身矛盾的关键。
- voter一定在投票给leaderU之前已经接受了来自leaderT的committed entry;否则它将拒绝来自leaderT的AppendEntry request(因为它的current term已经高于了T)。
- 当voter投票给leaderU的时候它依然保有该entry,因为每个intervening leader都包含该entry(根据假设),leader从不删除entry,而follower只删除它们和leader矛盾的entry。
- voter投票给leaderU,因此leaderU的log一定和voter的log一样up-to-date。这就产生了两个矛盾中的其中一个。
- 首先,如果voter和leaderU共享同一个last log term,那么leaderU的log至少要和voter的log一样长,因此它的log包含了voter的log中的每一个entry。这是矛盾的,因为voter包含了committed entry而假设中的leaderU是不包含的。
- 除非,leaderU的last log term必须比voter的大。进一步说,它必须大于T,因为voter的last log term至少是T(它包含了term T的committed entry)。之前创建leaderU的last log entry的leader必须在它的log中包含了committed entry(根据假设)。那么,根据Log Matching Property,leaderU的log必须包含committed entry,这同样是一个矛盾。
- 这就是矛盾所在。因此,所有term大于T的leader必须包含所有来自于T并且在term T提交的entry。
- Log Matching Property确保了新leader也会包含那些间接committed的entry,例如Figure 8(d)中的index 2。
给定Leader Completeness Property,证明Figure 3中的State Machine Safety Property就比较容易,即让所有的state machine以相同的顺序执行同样的log entry。
5.5 Follower and candidate crashes
在此之前我们都在重点研究leader failures。follower和candidate的崩溃比起leader的崩溃要容易处理得多,而且它们的处理方式相同。如果一个follower或者candidate崩溃了,那么后面发送给它的RequestVote和AppendEntry RPC都会失败。Raft通过不断地重试来处理这些故障;若崩溃的服务器重启了,那么后面的RPC就会生效。如果server在RPC生效后但在回复前崩溃了,那么它会在重启之后收到同样的RPC。但是Raft的RPC是幂等的(idempotent),因此不会造成什么问题。比如一个follower接收了包含一个已经存在于log中的AppendEntry request,它会直接忽略。
5.6 Timing and availability
我们对于Raft的一个要求是,其安全性不能依赖于时间:系统不会因为有些事件发生地比预期更快或更慢而产生错误的结果。然而,可用性(系统及时响应client的能力)将不可避免地依赖于时间。比如,由于server崩溃造成的信息交换的时间比通常情况下来得长,所以candidate就不能停留足够长的时间来赢得选举;而没有一个稳定的leader,Raft将不能进一步执行。
leader选举是Raft中时间作用最重要的地方。当系统满足以下的时间要求的时候,Raft就能够选举并且维护一个稳定的leader:
broadcastTime << electionTimeout << MTBF
(广播时间 << 选举超时时间 << 故障时间间隔)
在这个不等式中,broadcastTime是server并行地向集群中的每个server发送RPC并且收到回复的平均时间;electionTimeout就是如Section 5.2中描述的选举超时;MTBF是单个server发生故障的时间间隔。broadcastTime必须比electionTimeout小几个数量级,这样leader就能可靠地发送heartbeat message从而防止follower开始选举;通过随机化的方法确定electionTimeout,该不等式又让split vote不太可能出现。electionTimeout必须比MTBF小几个数量级,从而让系统能稳定运行。当leader崩溃时,系统会在大概一个electionTimeout里不可用;我们希望这只占整个时间的很小一部分。
broadcastTime和MTBF都是底层系统的性质,而electionTimeout是我们必须要进行选择的。Raft的RPC通常要求接收者持久化信息到stable storage,因此broadcastTime的范围在0.5ms到20ms之间,这取决于存储技术。因此,election timeout可以取10ms到500ms。通常,server的MTBF是几个月或者更多,因此很容易满足timing requirement。
6 Cluster membership changes
到目前为止,我们都假设集群配置(参与共识算法的server集合)是固定的。但实际上,偶尔改变配置是必要的,比如在server发生故障时将其移除或者改变复制程度。虽然这可以通过停止整个集群来更新配置文件,再重启集群实现,但是这会让集群在转换期间变为不可用。此外,如果其中存在手动操作的话,还会产生操作失误的风险。为了防止上述情况的发生,我们决定将配置变更自动化,并且将其和Raft共识算法结合起来。
为了保证配置更改机制的安全性,在转换期间的任意时刻,不能在一个term期间有两个leader存在。不幸的是,任何从旧配置转换到新配置的方法都是不安全的。不可能一次性对所有server进行自动转换,所以在转换期间集群会被潜在地分为两个独立的majority(见Figure 10)。
为了保证安全性,配置更改必须使用二阶段(two-phase)的方法。有很多种方法可以实现实现two-phase,比如有些系统使用first phase来禁用旧配置,从而不能处理client的请求;然后在second phase中使用新配置。在Raft中,集群首先转换到一个过度的配置,我们称作joint consensus;一旦joint consensus被提交之后,系统就过渡到新配置。joint consensus同时结合了旧配置和新配置。
- log entry会被备份到两个配置的所有server中
- 来自任意配置的server都可能会成为leader
- Agreement(election和entry的commitment)需要由旧配置和新配置的majority达成
joint consensus允许个别server在不破坏安全性的情况下,在不同的时间进行配置的过渡。另外,joint consensus允许集群在配置转换期间依旧能够处理来自client的请求。
集群的配置被存储在replicated log的special entry中,并且通过它来进行通信;Figure 11说明了配置改变的过程。当leader收到了一个将配置从Cold转换到Cnew请求,它会将joint consensus的配置(figure中的Cold,new)作为一个log entry存储并且使用上文描述的机制进行备份。一旦一个给定的server将一个新配置的entry加入它的log中,它就会在以后所有的decision中使用该配置(server总是使用它log中的最新配置,不管该entry是否被committed)。这意味着leader会使用Cold,new的规则来决定何时Cold,new的log entry被committed。如果该leader崩溃了,一个新的leader可能使用Cold或者Cold,new,这取决于赢得选举的candidate是否收到了Cold,new。任何情况下,Cnew都不能在这个阶段做单方面的决定。
一旦Cold,new被committed,Cold或者Cnew就不能在没有对方同意的情况下单独做决定了,而Leader完整性则确保了Cold,new的log entry的server才能被选作leader。现在leader创建一个描述Cnew的log entry并且将它备份到整个集群是安全的。同样,这个配置只要server看到它就会生效。当新的配置在Cnew的规则被committed时,old 配置就不再有效了,而那些不在新配置中的server就会被关闭。如Figure 11所示,没有一个时刻,Cold或者Cnew会单方面做决定,这就保证了安全性。
对于重新配置(reconfiguration)还有三个问题需要处理。第一个问题是新加入的server可能初始的时候没有存储任何log entry。如果它们以这种状态直接添加进集群,可能会花费相当多的时间让它们赶上来,而在这期间就不能提交新的log entry了。为了避免可用性差距(availability gaps),Raft在配置变更之前引入了一个附加项,在这期间新的server作为non-voting member(leader将log entry向它们备份,但是在计算majority时,并不考虑它们)加入集群。一旦新加入的server赶上了集群中的其他server之后,reconfiguration就会按照上面描述的步骤进行。
第二个问题是集群的leader可能并不包含在新配置中。在这种情况下,leader一旦提交了Cnew log entry之后leader就会step down(返回follower的状态)。这意味着会有这样一段时间(当在commit Cnew)时,leader可能会管理一个并不包含它自己的集群;它备份log entry,但是并不把它自己考虑在majority的计算中。leader的转换会在Cnew被committed之后发生,因为这是新配置可以独立运行的第一步(总是可以在Cnew中选出一个leader)。在这之前,只有Cold中的server才会被选为leader。
第三个问题是被移除的server(那些不在Cnew中的server)可能会破坏集群。这些server不会收到heartbeats,所以它们会timeout并且开始new election。于是它们会用新的term number发送RequestVote RPC,这会导致current leader恢复到follower的状态。一个新的leader最终会被选举出来,但是removed server还会再次timeout,而这个过程会不断重复,最终导致可用性非常差。
为了防止这样的情况发生,server会无视RequestVote RPC,如果它们认为current leader依旧存在的话。特别是一个server在election timeout内收到了一个RequestVote RPC,那么它不会更新它的term或者进行投票。这不会影响正常的选举,在开始election之前每个server都至少等待一个最小的election timeout。而这避免了removed server带来的破坏;如果一个leader能够从它的集群中得到heartbeat,那么它就不会受到更大的term number的影响。
7 Clients and log compaction
由于篇幅的原因本章就略过了,但是相关的资料在本论文的扩展版中可以获得。其中描述了client如何和Raft进行交互,包括client怎么找到cluster leader以及Raft如何支持线性语义(linearizable semantics)。扩展版本中还描述了如何利用快照(snapshotting)的方法回收replicated log的空间。这些问题在所有一致性系统(consensus-based system)中都会出现,Raft的解决方案和它们是类似的。
8 Implementation and evalution
我们已经将Raft作为存储RAMCloud配置信息的replicated state machine实现并且协助RAMCloud coordinator的故障转移。Raft的实现大概包含2000行C++代码,不包括测试,注释以及空白行。源代码可以自由获取。同时还有25个基于本论文的关于Raft的独立第三方开源实现。同时,还有各种公司在部署Raft-based systems。本节的剩余部分将从可理解性,正确性以及性能三个标准来评估Raft。
《In Search of an Understandable Consensus Algorithm》译文
https://lameber1123.github.io/2022/01/21/《In-Search-of-an-Understandable-Consensus-Algorithm》翻译/