openGauss存储技术
- 存储概览
- 行存储引擎
- 列存储引擎
- 内存引擎
目录
1 openGauss存储概览
早期计算机程序通过文件系统管理数据,到了20世纪60年代,用户逐渐对数据并发写入的完整性、高效的检索提出更高的要求。由于机械磁盘的随机读写性能问题,从20世纪80年代开始,大多数数据库一直围绕着减少随机读写磁盘进行设计。主要思路是把对数据页面的随机写盘转化为对WAL(Write Ahead Log,预写式日志)的顺序写盘,WAL持久化完成,事务就算提交成功,数据页面异步将数据刷新到磁盘上。
但是随着内存容量变大和保电内存、非易失性内存的发展,以及SSD(固态硬盘)技术的逐渐成熟,磁盘的IO性能得到极大提高,经历了几十年发展的存储引擎需要调整架构来发挥SSD的性能和充分利用大内存计算的优势。随着互联网、移动互联网的发展,数据量剧增,业务场景呈现多样化,一套固定不变的存储引擎不可能满足所有应用场景的诉求。因此现在的DBMS需要设计支持多种存储引擎,根据业务场景来选择合适的存储模型。
1.1 存储引擎要解决的问题
- 存储的数据必须要保证原子性(A)、一致性(C)、隔离性(I)、持久性(D)。
- 支持高并发读写,高性能。
- 充分发挥硬件的性能,解决数据的高效存储和检索能力。
1.2 存储引擎概述
openGauss整个系统设计是可插拔、自组装的,支持多个存储引擎以满足不同场景的业务诉求。当前openGauss存储引擎有以下3种:
- 行存储引擎,主要面向 OLTP场景设计,例如订货、发货、银行交易系统。
- 列存储引擎,主要面向 OLAP场景设计,例如数据统计报表分析。
创建表的时候可以指定为行存储引擎表、列存储引擎表、内存引擎表,支持一个事务中包含对三种引擎表的DML(数据操作语言)操作,可以保证事务的 ACID性质。
2 行存储引擎
openGauss行存储引擎采用原地更新(in-place update)设计,支持 MVCC(Multi- Version Concurrency Control,多版本并发控制),同时支持本地存储和存储与计算分离的部署方式。行存储引擎的特点是支持高并发读写,时延小,适合OLTP交易类业务场景。
2.1 总体架构
openGauss的行存储引擎在设计上支持MVCC,采用集中式垃圾版本回收机制,可以提供 OLTP业务系统的高并发读写要求,支持存储、计算分离架构,存储层异步回放日志。
数据页面缓存池中缓存数据页面,在数据页面中存放元组以及元组的历史版本并集中管理,使用Vacuum(垃圾清理)线程进行定期的空间回收。
行存储引擎的关键技术有:
- 基于事务ID以及ctid(行号)的多版本管理。
- 基于CSN(CommitSequenceNumber,待提交事务的序列号,它是一个64位递增无符号数)的多版本可见性判断以及MVCC机制。页面,在数据页面中存放元组以及元组的历史版本并集中管理,使用Vacuum(垃圾清理)线程进行定期的空间回收。
- 基于大内存设计的缓冲区管理。
- 平滑无性能波动的增量检查点(checkpoint)。
- 基于并行回放的快速故障实例恢复。
2.2 基本模型与页面组织结构
行存储的元组结构以及页面组织,是行存储DML实现、可见性判断以及行存储各种功能与管理机制的基石。
行存储是基于磁盘的存储引擎,存储格式的设计遵从段页式设计。存储结构需要以页面为单位,方便与操作系统内核以及文件系统的接口进行交互。也是由于这个原因,页面的大小需要和目标系统中一个block(块)的大小对齐。在比较通用的Linux内核中,页面大小一般默认为8KB。一个基本的Heap(堆)页面如下图所示。

页面开头的位置为整个页面的头部信息,记录了这个页面的公用信息以及一些关键标识。line_pointer被放置于Header后面,并向页面尾部扩展。line_pointer为指向Tuple实际数据的一个指针,类似于行指针的作用。
而每个Tuple在系统中的唯一标识ItemPointer,也被称为ctid,存储的是这一行所在的页面号以及其对应的line_pointer的偏移量(offset)。这样由一个系统内记录的ctid,可以快速定位到这个Tuple的line_pointer,就可以根据line_pointer的指针快速定位到Tuple的实际数据。
line_pointer的必要性显而易见。由于Tuple的数据内容是变长的,因此读取Tuple需要遍历页面结构;而line_pointer结构本身为定长,因此可以直接以常数的复杂度找到数据所在内存位置。line_pointer的sentinel效果也十分明显:line_pointer的存在使得Tuple的对应改动局限于页面内部,而保持全局标识ctid不发生变化;如果没line_pointer,行更新则需要连带更新的元信息、索引以及系统各处信息,复杂度会上升。
被line_pointer指向的行记录本身,从页面结尾开始向页面头部延展,避免在页面填充过程中的数据移动以及空间浪费。
页面头部的Header中储存了如下信息:
- pd_lsn为最后一次改动此页面事务写下的WAL(xlog)的下一位,被xlog机制以及检查点机制所使用。
- pd_checksum 为页面中的checksum,为了检查页面的完整性和一致性使用。
- pd_flags是此页面的标识位,可以让上层通过对此页面进行处理的接口快速识别此页面的一些特征,比如页面是否有空行,页面是否写满,页面是否已经对所有事务全部可见,页面是否被压缩等。
- pd_lower和pd_upper是指向页面空闲空间起止的指针,即pd_lower指向下一个line_pointer的位置,而pd_upper指向下一个行记录数据填充的位置,这样既可以快速进行页面的填充修改,也可以方便计算页面的空闲空间。
- pd_special指针用于记录一些特殊的存储管理方式以及接口所需的内存区域。
- pd_prune_xid记录上一次对此页面进行清理的xid(事务ID,事务号)。
- pd_xid_base以及pd_multi_base为这个页面上xid的base基准,即该页面上所有的记录的xid都由页面自身记录的 xid(32位)与 base(64位)计算得到,是64位xid的实现方式。
记录(元组的数据部分)是数据库中最基本的数据存储单位,其自身的结构以及记录的信息也是系统中数据存储方式、DML、事务 ACID 特性的关键。数据部分结构图如下:

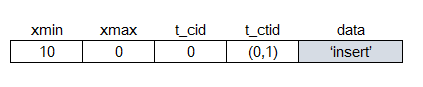
- xmin是最初始的事务ID(Transaction ID,简称xid),即插入此条记录的事务ID。
- xmax是删除或更新此条记录的xid。如果此记录未被更改或删除,那么xmax为0。
- t_cid记录的是命令ID(Command ID),命令ID 用于一个事务内部多步操作的一种记录与跟踪。
- t_ctid记录了此条记录的ctid值,或者是更新版本的ctid值。这个会在后面展开 DML时讲到。
- 两个t-infomask是事务以及存储数据状态的标识位,用于快速判断。
xmin、xmax两个事务ID,结合其映射的 Clog(提交日志)和 CSN Log,一同构成了可见性判断的核心关键要素。
2.3 行存储的多版本管理以及 DML操作
openGauss行存储的多版本机制与业界比较常见的关系数据库有较大的不同,核心区别为行存储的多版本在更新的时候并不是就地更新,而是在原有页面中保留上一个版本,转而在这个页面(如果空间不够会在新页面中)中创建一个新的版本进行历史版本的累积与更新。
相应的页面中会同时存有不同版本的同一行数据,拿到不同快照的事务,在读写这些不同版本时互不冲突,有着很好的并发性能。对历史版本的检索可以在页面本身或邻近页面进行,也不需要额外的CPU开销以及IO开销,有着非常高的效率。同时,事务管理以及持久化角度也变得非常清晰简洁,省去了类似于就地更新所需要的记录、执行以及持久化的 Undo(回退)等相关操作。
以下就以一个 DML的例子简单介绍行存储结构以及 MVCC的实现。
假设我们在一个xid为10的事务中,在一个只有一列varchar(变长字符串类型) 数据的表中插入一条数据 ‘A’,该行数据存入编号为0的数据页面上,则该行存储结构如图所示。