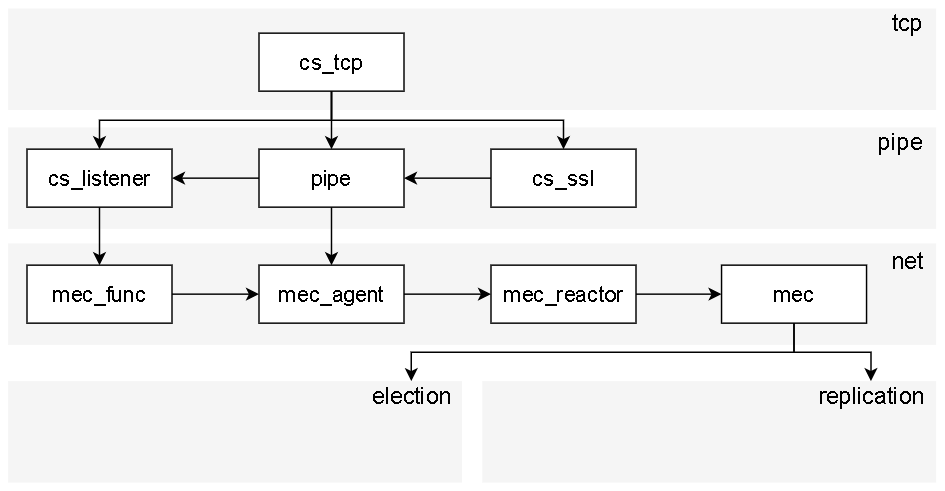
DCF心跳机制
- 关于心跳机制
- DCF的选举与心跳机制
- 采用rdma实现心跳
目录
1 关于心跳机制
在集群中,往往采用类paxos一致性协议来实现高可用。集群至少设定leader、follower两种节点状态,集群中的工作由leader状态的节点主持进行。
举个例子,当A、B、C组成的新集群启动时,A、B、C默认的状态均是follower。
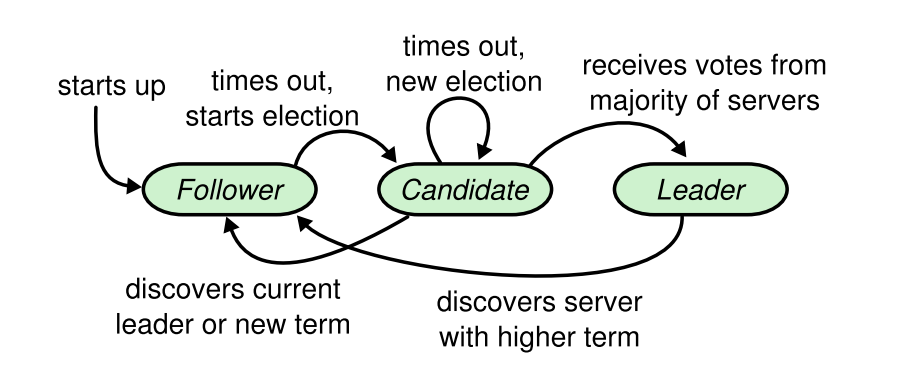
如果有节点收到心跳,则作为follower开始工作,选主结束。如果超过一段时间后,开始发起选举(election)。这段时间称为选举超时时间,在一定范围随机且大于心跳时间。其随机的目的是为了避免同时发起选举的情况。
因为集群初始化时没有leader,所以没有节点会收到心跳,节点A开始发起选举。首先把自己的身份置为candidate,将term自增,并且投票给自己。
- 当B收到这个投票请求时,如果发现candidate的term小于自身,则拒绝,并返回自身term。
- 如B发现candidate的term大于自己,就更新term,并且重置votedFor为A。
- 如果B发现当前term已经给别人投票过,则拒绝。
- 如果B发现candidate的日志不是最新,则拒绝。
- 没有拒绝的理由,则给A投票。
节点A在发送投票请求后,进行判断。
- 如果收到了大多数赞成票,则跳到步骤7,成为新leader。
- 如果发现返回的term大于自己,就放弃本轮选主,并更新自身term,重置状态为follower,重新开始步骤1。
- 如果节点A在投票结束后,没有收到大多数赞成票,则返回步骤2,发起新一轮选举。
- 如果节点A选主成功, 设置自身状态为leader, 并且立即发送一次心跳(避免其他节点因超时进入选主状态)。
周期性发送心跳, 保持leader状态。
简单来说,follower只响应来自其他节点的请求。如果follower长时间接收不到消息,那么就会成为candidate发起一次选举。如果获得集群中大多数选票,则会成为新leader。leader会保持自身状态直到宕机。
2 DCF的选举与心跳机制
2.1 对选举的优化
openGauss中引入了基于Paxos协议的DCF组件,DCF中实现了上述的选举与心跳机制。但在上数机制中进行了部分优化。
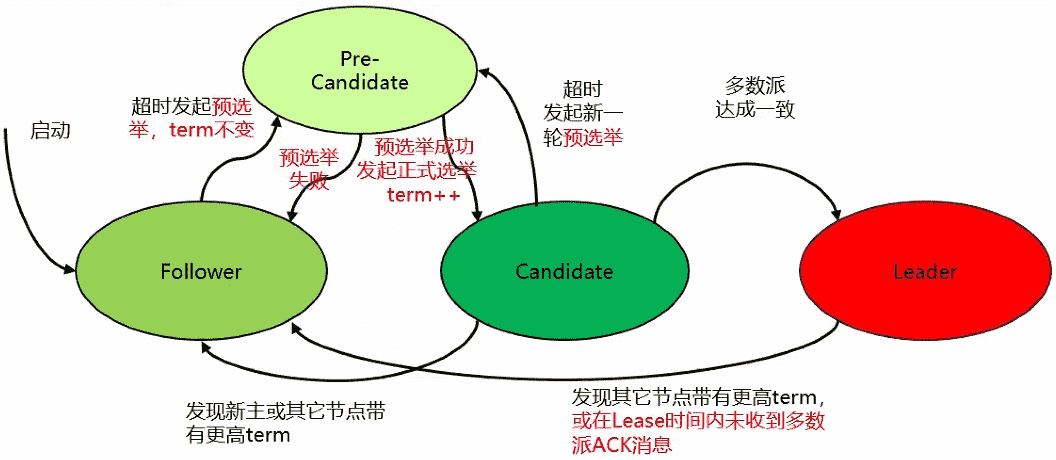
preVote优化:
- 为防止网络断连导致节点频繁发起选主请求,term持续增加
- 在Follower变为Candidate前加入pre-candidate状态,发起term不变的预选举流程,成功后才将term++发起正式选主流程
Lease优化:
- Leader与多数派断连主动降备,防止事实双主
- 在lease时间内不响应term更高的选主消息
DCF在Paxos上增添了预选举环节选举测试,增加一次探测,当与大多数节点通信正常时才会发起选举,获得大多数节点的投票后当选为主节点,然后所有Follower跟随主节点做日志的同步。
2.2 选举测试
下面,先使用DCFTest对DCF的选举进行简单的测试,通过日志观察一下DCF节点的选举流程。本次参与集群测试的三台服务器初始配置如下:
{“stream_id” : 1, “node_id” : 1, “ip” : “172.19.0.202”, “port” : 29222,”role” : “LEADER”},
{“stream_id” : 1, “node_id” : 2, “ip” : “172.19.0.203”, “port” : 29222, “role” : “FOLLOWER”},
{“stream_id” : 1, “node_id” : 3, “ip” : “172.19.0.204”, “port” : 29222, “role” : “FOLLOWER”}
首先打开三台服务器服务器,运行DCFTest
cd DCFTest
sh build.sh
query
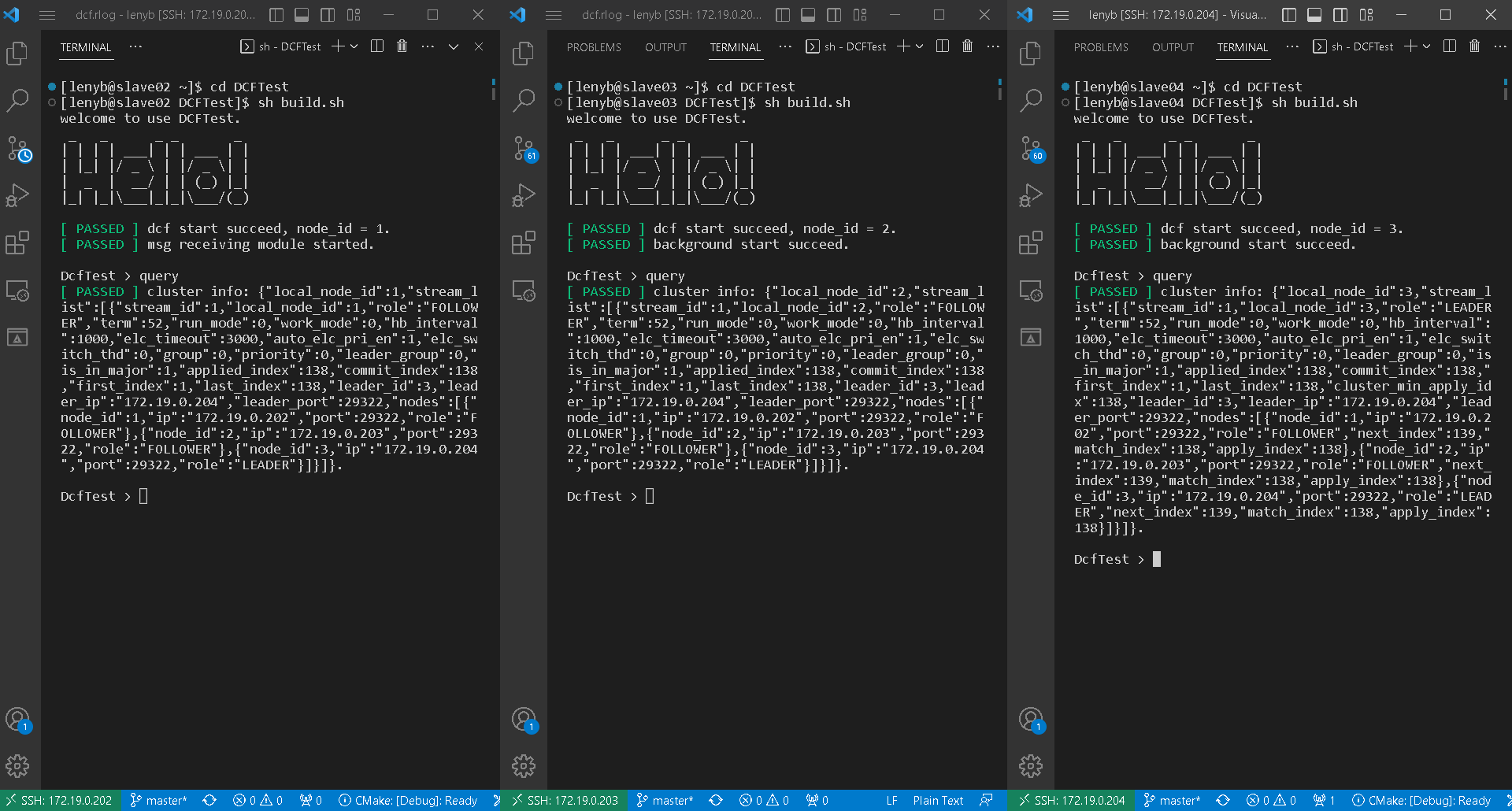
可见DCFTest节点均正常启动与运行,node3当选为leader节点。他的部分选举日志(dcf.rlog)如下:
node1、node2的follower状态不变。以node1为例,其部分选举日志(dcf.rlog)如下:
以上的日志中,我只保留了选举有关日志,省略了网络等部分的日志。因为node3在上一次运行时作为leader,所以最早没有等待心跳,直接发起了预选举(pre-voting)。此时的node1、node2还在等待超时时间,一收到node3的投票请求后就赞成投票。所以node3预选举成功,发起正式选举,同样收到了二者的赞成票,正式选举成功,当选新leader。值得注意的是,三个节点的集群中,两票就满足了大多数原则,所以node3在收到node2的选票时,不再等待node1的回复,直接当选。
2.3 心跳测试:正常情况
从上述测试产生的日志中可以看出DCF的选举流程,不过并不能完整展现DCF的心跳机制。下面将通过更多测试产生的日志展示心跳机制。
首先,通过dcf.dlog中记录的日志,可以看出集群正常状态下的心跳收发机制。下面显示了一次心跳发送与确认有关的日志。
node1(follower):
node2(follower):
node3(leader):
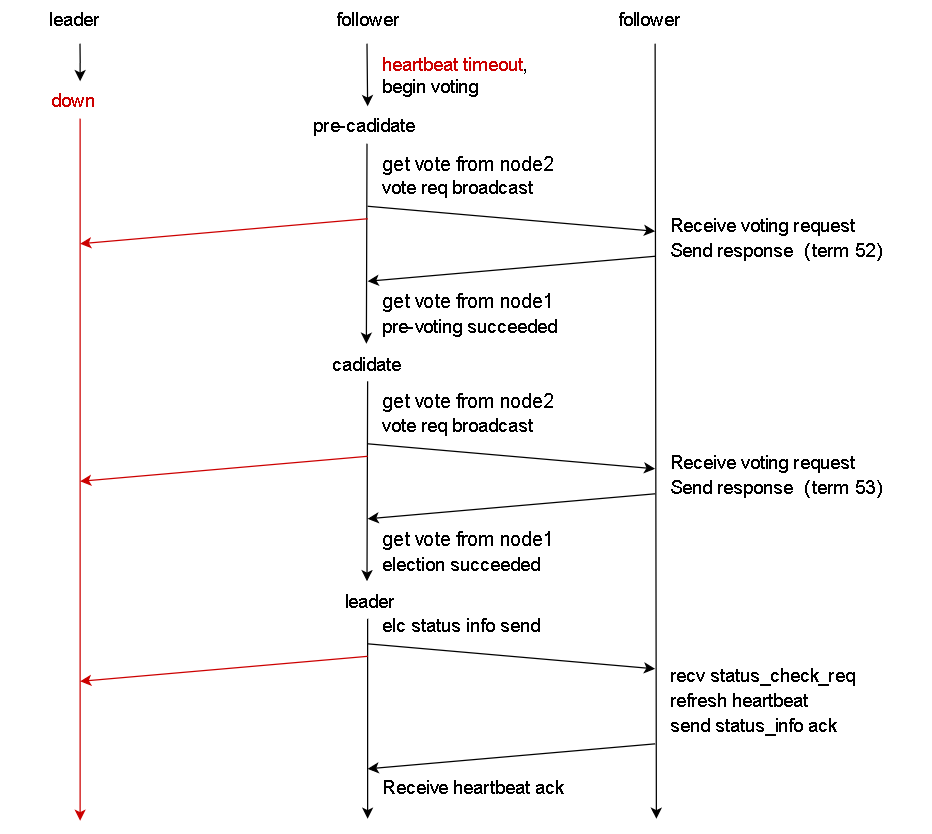
正常情况下,node3会定时向node1、node2发送心跳消息(日志命名为status info),两个follower节点在收到心跳消息后,刷新自身心跳,然后向leader节点返回确认(ack)消息。最后,leader收到两个follower节点的确认消息后,检查心跳ack消息与自身校验和是否一致。如下图所示:
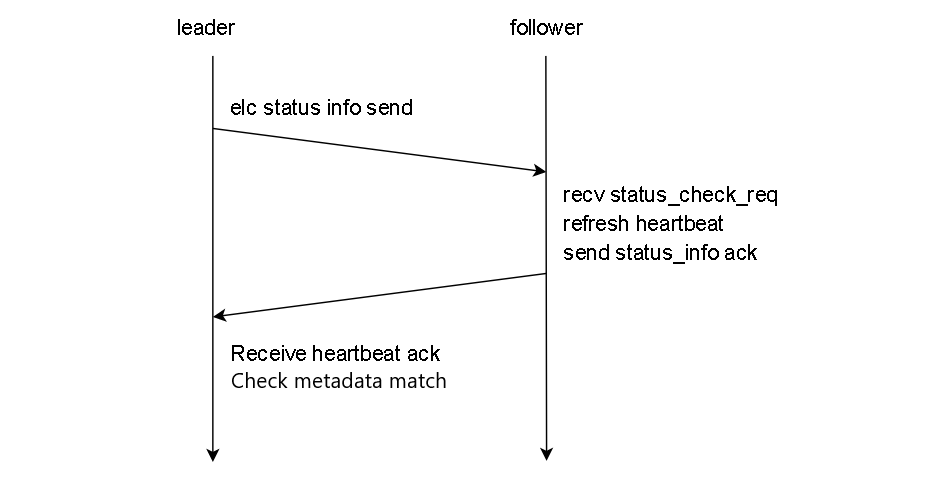
2.4 心跳测试:follower宕机
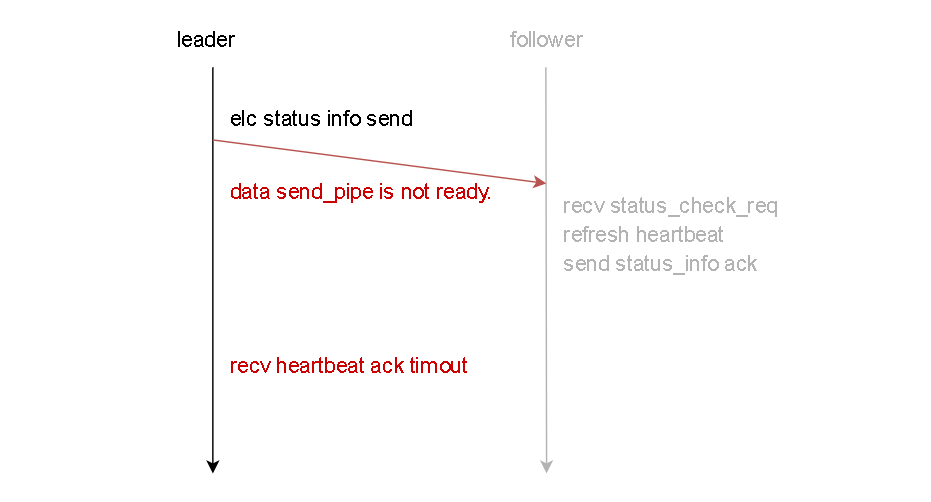
接下来,将node2节点手动宕机。此时node3发送的心跳信息无法被node2接收,自然也无法收到node2所返回的确认消息。手动将node2宕机后的部分node3日志如下:
如日志所示,node3再向node2发送心跳消息时会报错,提示数据send_pipe不存在,并提示接收node2的心跳确认消息超时。如下图所示:
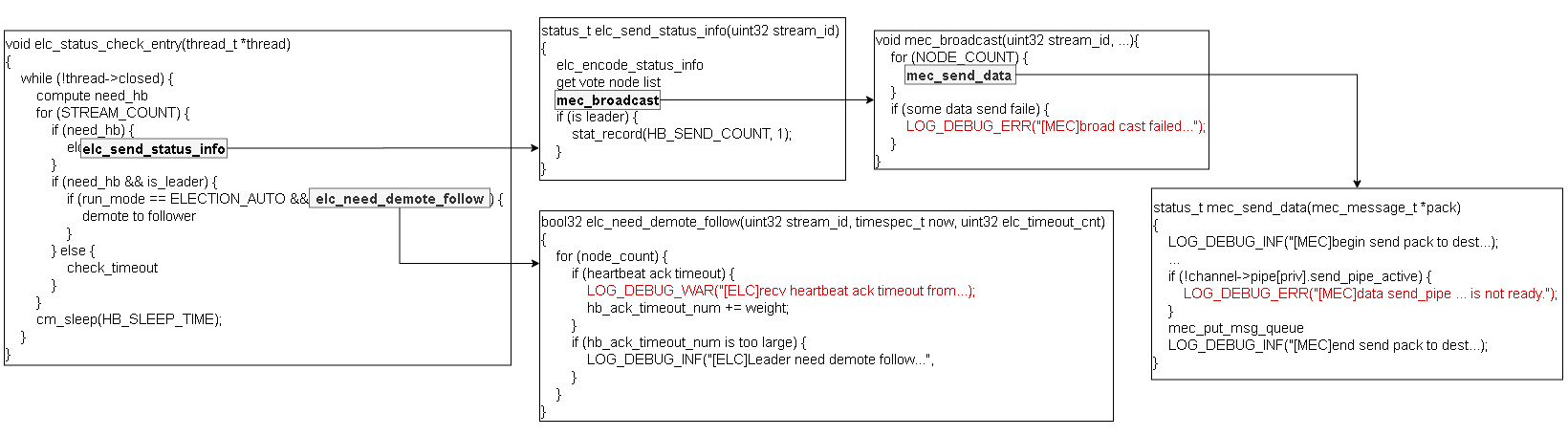
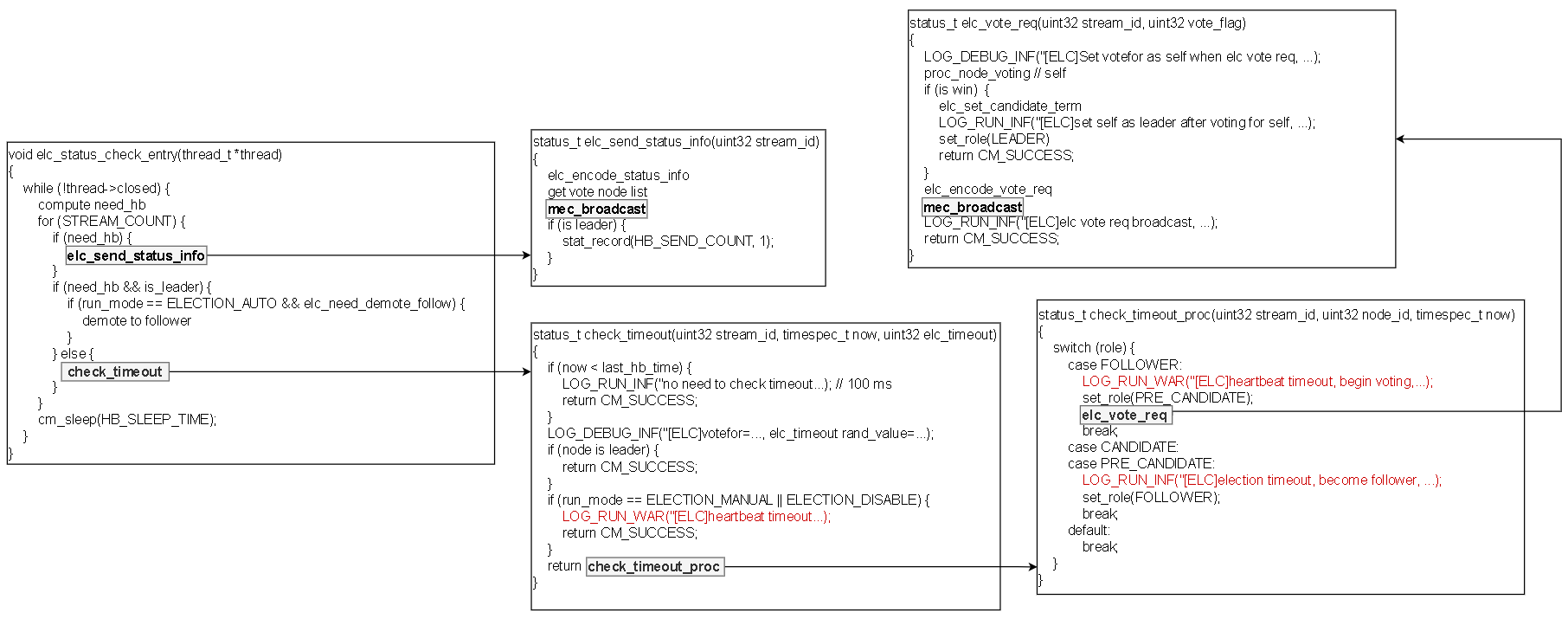
在代码层面上看,leader的心跳发送机制实现于elc_status_check_entry函数中,该函数在elc_init函数中被创建子线程运行。在elc_status_check_entry函数中,leader会定期发送status_info,并检查是否有follower节点的确认消息超时。如果发送消息的mec_send_data函数检测到与follower节点间的pipe失效,则会报错,进而提示广播失败。
最后手动将node2节点恢复运行,集群的心跳状态恢复到正常情况。
2.5 心跳测试:leader宕机
在node1、node2与node3均正常运行的情况下,将node3节点(leader)手动宕机。此时node1与node2将无法收到node3的心跳消息,发起新一轮选举,二者有关选举日志如下。
node1(follower):
node2(follower->leader):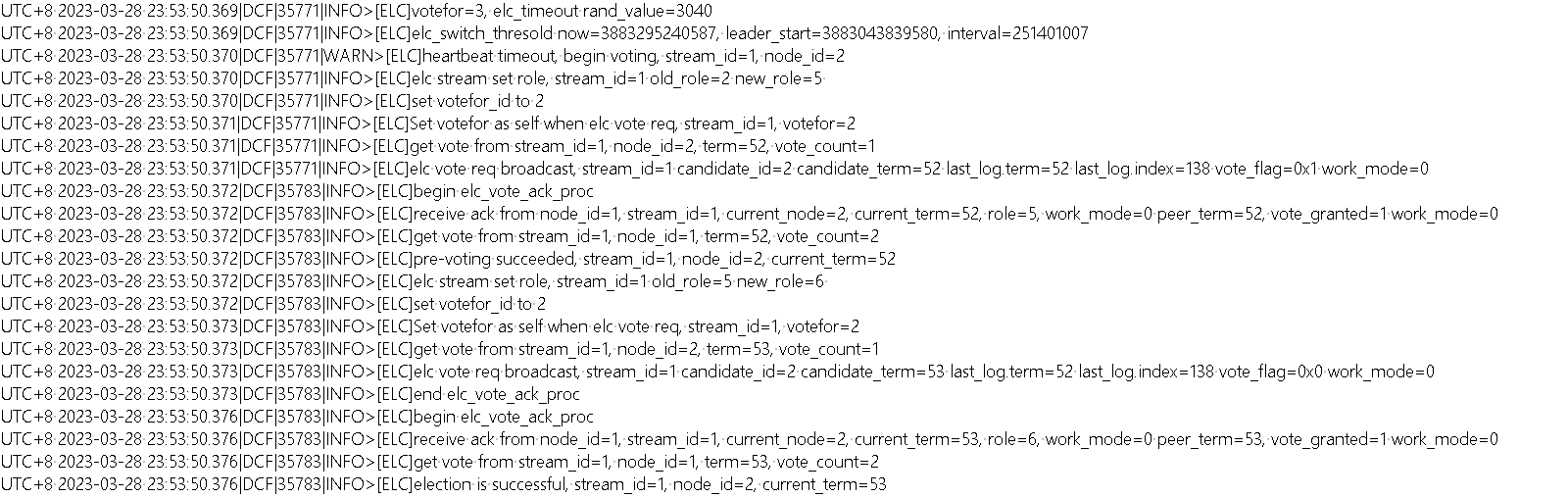
如日志所示,node3再向node2发送心跳消息时会报错,提示数据send_pipe不存在,并提示接收node2的心跳确认消息超时。如下图所示:
在代码层面上看…
3 使用Lnet实现心跳
由于DCF的心跳是在tcp网络上发送的,时间上还有优化的可能。下面将尝试将基于tcp网络的心跳机制改为基于rdma技术的心跳机制,rdma采用Lnet库实现。
Lnet项目地址:https://github.com/NPUWDBLab/lnet/tree/zyp-dev
经如下的代码结构观察,初步想法是用rdma的接口平行的替换原有tcp的接口。